

Introduction
After many years of working with enterprise content management systems, one constant challenge remains: maintaining rich, consistent metadata across large asset libraries. While Sitecore Content Hub provides excellent tools for metadata management, the initial task of generating detailed descriptions for tens or even hundreds of thousands of assets can be a daunting task. Managing metadata for thousands of images can be daunting for any organization. I will provide an approach and some cold examples for quickly creating metadata for the content hub assets using open AI vision API this approach can be applied to other dams and content management systems such a site core exam, XP and cloud or any other system for that matter
The Metadata Challenge
Content Hub's value as a Digital Asset Management (DAM) system largely depends on the quality of its metadata. Good metadata enables:
Precise asset searching and filtering
Automated workflow triggers
Content reuse and repurposing
Compliance and rights management
However, manually creating detailed descriptions for large image collections is time-consuming and often inconsistent. This can be even more challenging in specialized domains, for example, in real estate photography, where descriptions need to capture specific architectural features, materials, and design elements.
Enter GPT-4 Vision
OpenAI's GPT-4 Vision API offers a powerful solution. It can analyze images and generate detailed, structured descriptions that capture the nuances of architectural photography. We've developed a Python script that:
Processes images in parallel for efficiency
Generates consistent, detailed descriptions
Maintains proper error handling and logging
Integrates smoothly with Content Hub workflows
The Implementation
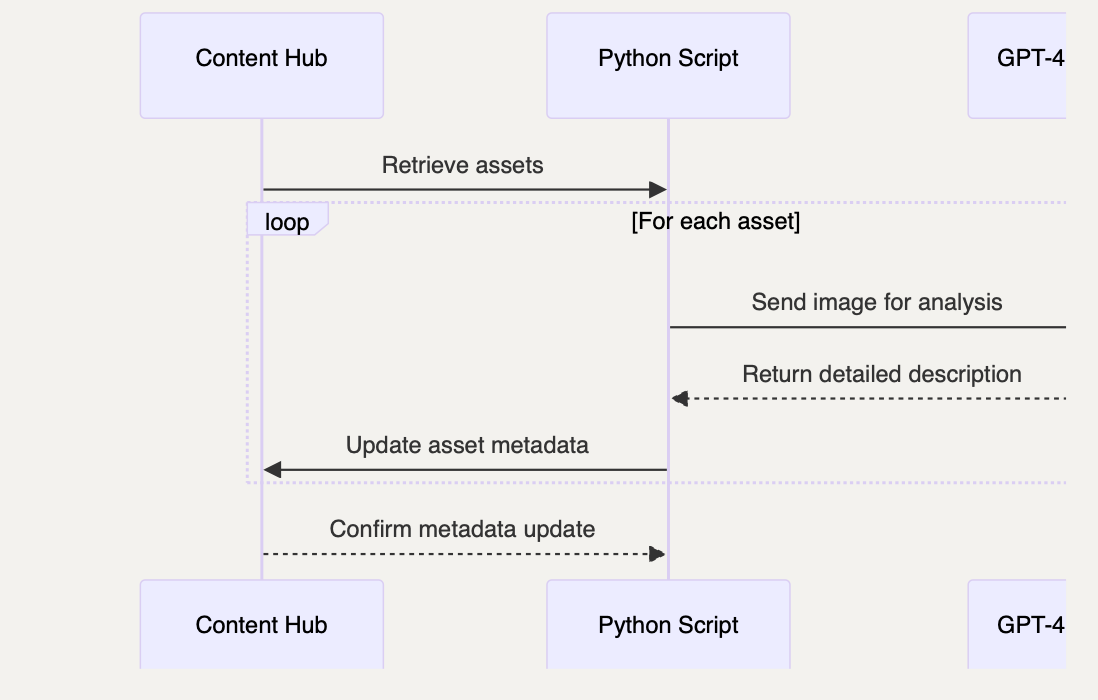
My solution is essentially a Python script which operates on a massive set of downloaded assets, running multiple assets in parallel against the ChatGPT vision model to generate in this case a description What is depicted on the image. In this case, I had a specific requirement for AI to recognize whether or not an asset is a real photograph or something else, such as digital render or plan, so that these assets can be later used for machine learning. Feel free to update the prompt to match your requirements, which may include, for example, recognizing and naming specific landmarks, lighting conditions, weather, products, etc., etc.
I would like to note that Content Hub already is using Azure Cognitive Services for image analysis, which results in a list of descriptive tags, and may just be enough for your needs, but if not, then here is my approach.
So, without further ado, here's the Python script, to query an image asset with vision api and then save generated description in the text file with the same name. In my case, I needed to eliminate all non-photographic assets, so I have some additional logic for that. Feel free to remove that, update prompt, etc., to meet your specific needs.
#!/usr/bin/env python3
"""
Metadata Generator for AI Training Images
This script processes a directory of images using OpenAI's GPT-4 Vision API to generate
detailed architectural descriptions for AI training.
"""
import os
import logging
import ray
from openai import OpenAI
import base64
from typing import List, Tuple, Optional
from datetime import datetime
# Configuration
NUM_THREADS = 6 # Adjust based on your CPU cores
API_KEY = "[your open ai api key here]"
# Set up logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('metadata_generation.log'),
logging.StreamHandler()
]
)
# run in parallel to speed up the whole process
@ray.remote
class ImageProcessor:
"""
Handles image processing and caption generation using GPT-4 Vision.
Designed for parallel processing of architectural images.
"""
def __init__(self, api_key: str):
self.client = OpenAI(api_key=api_key)
self.processed_count = 0
def encode_image(self, image_path: str) -> Optional[str]:
"""Convert image to base64 encoding for API submission."""
try:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
except Exception as e:
logging.error(f"Error encoding image {image_path}: {e}")
return None
def generate_caption(self, image_path: str) -> Tuple[str, Optional[str]]:
"""
Generate an architectural description using GPT-4 Vision.
Returns (image_path, caption) tuple.
"""
try:
base64_image = self.encode_image(image_path)
if not base64_image:
return image_path, None
prompt = """
Analyze this architectural image and create a detailed description using
10-15 descriptive phrases. Focus on:
- Room type and size
- Key architectural features
- Materials and finishes
- Lighting conditions
- Design style
Format as comma-separated phrases starting with the room type.
"""
response = self.client.chat.completions.create(
model="gpt-4-mini",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
]
)
self.processed_count += 1
if self.processed_count % 10 == 0:
logging.info(f"Processed {self.processed_count} images")
return image_path, response.choices[0].message.content.strip()
except Exception as e:
logging.error(f"Error processing {image_path}: {e}")
return image_path, None
def get_image_files(folder_path: str) -> List[str]:
"""Return list of supported image files in the given folder."""
supported_formats = {".jpg", ".jpeg", ".png"}
return [
os.path.join(folder_path, f) for f in os.listdir(folder_path)
if os.path.splitext(f)[1].lower() in supported_formats
]
def save_caption(result: Tuple[str, Optional[str]]) -> None:
"""Save generated caption to a text file alongside the image."""
image_path, caption = result
if caption:
txt_path = os.path.splitext(image_path)[0] + ".txt"
try:
with open(txt_path, "w") as txt_file:
txt_file.write(caption)
logging.info(f"Caption saved for {os.path.basename(image_path)}")
except Exception as e:
logging.error(f"Error saving caption for {image_path}: {e}")
else:
logging.warning(f"No caption generated for {image_path}")
def main():
"""Main execution function for metadata generation."""
start_time = datetime.now()
logging.info(f"Starting metadata generation at {start_time}")
# Initialize Ray for parallel processing
ray.shutdown()
ray.init(num_cpus=NUM_THREADS)
try:
folder_path = "training_images" # Update with your image folder path
image_files = get_image_files(folder_path)
if not image_files:
logging.warning("No images found in the specified folder")
return
# Skip images that already have captions
image_files = [
f for f in image_files
if not os.path.exists(os.path.splitext(f)[0] + ".txt")
]
if not image_files:
logging.info("All images already have captions")
return
# Create processor actors for parallel processing
processors = [ImageProcessor.remote(API_KEY) for _ in range(NUM_THREADS)]
# Distribute work among processors
futures = []
for i, image_path in enumerate(image_files):
processor = processors[i % NUM_THREADS]
futures.append(processor.generate_caption.remote(image_path))
# Process results as they complete
for future in ray.get(futures):
save_caption(future)
except Exception as e:
logging.error(f"Error in main execution: {e}")
finally:
ray.shutdown()
end_time = datetime.now()
duration = end_time - start_time
logging.info(f"Metadata generation completed in {duration}")
if __name__ == "__main__":
main()
Conclusion
The integration of AI-powered metadata generation with Content Hub marks a significant leap in real estate digital asset management. By harnessing GPT-4 Vision, we've optimized the creation of detailed asset descriptions, enhancing both efficiency and quality. This fusion of Content Hub's robust features with AI-generated metadata unlocks new potential in asset utilization and workflow automation.
While challenges persist in fine-tuning AI outputs for specialized terminology, the benefits are evident. This project showcases how enterprise DAM systems can evolve to meet modern content strategy demands, ultimately boosting value in marketing and sales processes.
Useful links
Ray: Distributed Computing Framework
Enterprise Content Management Systems
Digital Asset Management (DAM)