

Sitecore Search offers many types of Sources including Web Crawlers, Advanced Web Crawlers, Feed Crawler, Sales Feed Crawler, API Crawler, API Push, PDFs, and Localizer Crawler.
You should identify the type of source required based on the specific needs of your project. These decisions often depend on factors such as data recency, latency, and extensibility of the final implementation. If your project uses an API Push Source, this blog clarifies some of the practical questions that required a support ticket during implementation.
How to Know What Data Was Pushed to the Ingestion API
When using API Push Sources in Sitecore Search, developers must use the Ingestion API to keep the source updated. The Ingestion API allows you to add, update, or remove documents in near real time.
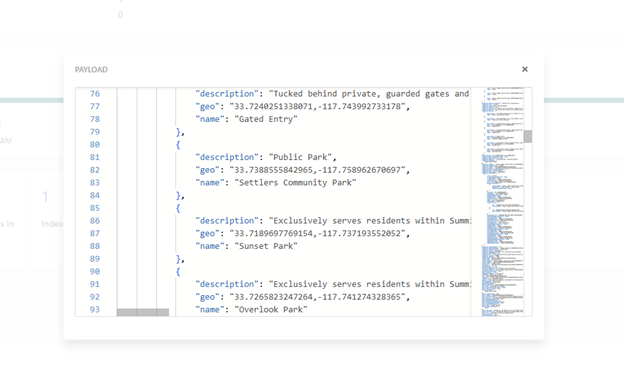
The API uses JSON payloads for CRUD operations. In the backend, developers create a JSON payload with operations such as Add, Update, or Delete to modify the source. During development, it is often necessary to verify the actual payload ingested by Sitecore Search to ensure that the data is correct. Access to the raw JSON is also useful for debugging production indexing issues. Sitecore Search provides a way to view the final JSON that was ingested.
To view the JSON consumed by Sitecore Search in the Search CEC, navigate to:
- Analytics → Sources → Overview
- Select the source to open the Source Dashboard
- Review the indexing batches
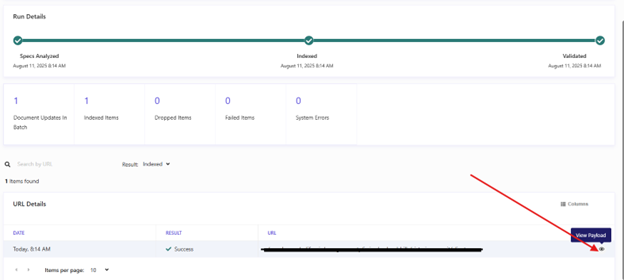
- Open a batch and click the Show icon next to an item
This will display the JSON payload that was processed by the search index.
Can I Remove All Documents from an API Push Source from the CEC?
During development, it is common for test or sample data to be pushed into the source. Sometimes developers need to reset the source and start with a clean dataset. There are two ways to achieve this.
- Archive and Delete the Source from CEC
If your frontend implementation does not depend on the source ID, you can archive and delete the source. After deletion, create a new source and update the configuration of the system that pushes data to the Ingestion API. - Remove Items Using PowerShell or Postman
In some scenarios, the source ID must remain unchanged because it is referenced by downstream systems. In this case, you can retrieve all document IDs from the source and call the Delete operation through the Ingestion API for each item. While this takes longer, it is the only way to clear the source while preserving the source ID and name.
What About Parallel Workers in API Push Sources?
For Web Crawlers, Sitecore Search allows configuration of parallel crawler threads to improve indexing performance. Multiple threads enable faster crawling of large websites.
Currently, API Push Sources do not provide a similar configuration for parallel workers. A support request has been raised and the feature is being considered by the product team.
In one implementation scenario, approximately 60 content authors publish updates that trigger indexing through an Edge Webhook. When many items are published simultaneously, you may observe slight delays in ingestion due to sequential processing of the updates.
How Do I Call an Authenticated Serverless Function from an Edge Webhook?
Item Webhooks allow OAuth credentials to be configured so that authentication tokens are automatically requested and passed to the receiving service. However, Edge Webhooks do not currently support this capability.
To address this limitation, Sitecore support recommended implementing a passthrough service that handles authentication before calling the final function.
In one project implementation, the following architecture was used:
- The publishing event triggers an Edge Webhook
- The Edge Webhook calls a passthrough API on the frontend head
- The head service adds authentication and forwards the request to an Azure Function
- The Azure Function constructs the final JSON payload
- The payload is sent to the Sitecore Search Ingestion API
These are a few practical considerations to keep in mind when working with API Push Sources in Sitecore Search. If you would like to explore these scenarios further or see them implemented in a real project, feel free to connect with me on LinkedIn or reach out through the Contact Us form.