

I've seen my fair share of challenges when it comes to moving content between different platforms. Recently, I faced an interesting task of my company's technical blog with over 10 years of content (mostly around Sitecore). In this post, I'll share my experience of migrating a lot of inconsistently written and formatted content from a legacy website to Sitecore Content Hub One. I'll walk you through the process of extracting content to Sitecore Content Hub One and provide you with a practical approach that you can use for your own content migration projects.
The Migration Approach
Before diving into the technical details, let me outline the approach I took to ensure a successful migration:
1. Content Extraction with javascript tools: I chose Puppeteer and Cheerio for content scraping. Puppeteer excels at handling dynamic JavaScript-heavy sites by providing a real browser environment, while Cheerio offers an efficient way to parse and extract content from HTML using familiar jQuery-like syntax. This combination proved to be powerful for handling various content structures and formats.
2. Content Refinement with AI: Over a decade of blogging naturally led to inconsistencies in formatting and writing style. I leveraged ChatGPT to standardize the content's tone and format while preserving the technical accuracy. This step significantly improved the overall quality and readability of the migrated content.
3. Uploading Content to Content Hub One: The final step involved pushing the refined content to Sitecore Content Hub One, taking advantage of its robust content modeling and API capabilities.
Here's a visual representation of the process:
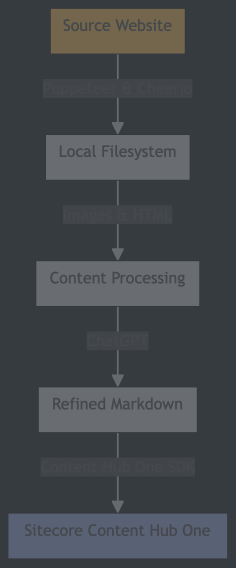
A note on the Sitecore Content Hub One
Sitecore Content Hub One is a headless content management system (CMS) designed to provide seamless content delivery across multiple channels. It offers flexibility and scalability, making it an ideal choice for modern digital experiences. As part of the broader Sitecore ecosystem, it provides powerful tools for content management and delivery.
Prerequisites
Before starting the migration process, ensure you have the following:
1. Node.js installed on your system
2. Access to Sitecore Content Hub One instance
3. Required npm packages: puppeteer, cheerio, turndown, @sitecore/contenthub-one-sdk
Step 1: Scraping Content from the Source Website
The first step in the migration process is to scrape content from the source website. This involves extracting text, images, and other relevant data. Our implementation uses Puppeteer for headless browsing and Cheerio for HTML parsing.
Setting Up the Scraper
// Import the required packages
const puppeteer = require("puppeteer");
const cheerio = require("cheerio");
const fs = require("fs");
const path = require("path");
// Configuration
// Set the root directory for storing the scraped data
const dataRoot = "./data";
// Set the root directory for storing the scraped pages
const pagesRoot = "./data/pages";
// Set whether to save images while scraping
const saveImages = true;
Implementing the Scraper
/**
* Extracts content from a given page and saves it to the file system.
*
* @param {string} page - The page URL to extract content from.
* @param {TurndownService} turndownService - The Turndown service instance for converting HTML to Markdown.
*/
const extractDetailsPages = async (page, turndownService) => {
const browser = await puppeteer.launch(); // Launch a headless browser instance
const page = await browser.newPage(); // Create a new page
// Navigate to the page
await page.goto(page); // Navigate to the page
const content = await page.content(); // Get the page content
// Parse content with Cheerio
const $ = cheerio.load(content); // Load the HTML content into Cheerio
// Extract content and save
const title = $("h1").text(); // Extract the title of the page
const bodyContent = $(".article-body").html(); // Extract the body content of the page
const markdown = turndownService.turndown(bodyContent); // Convert the HTML content to Markdown
// Save the content
await saveBlogData({
title,
content: markdown,
// Add other metadata
}); // Save the extracted content to the file system
};
Handling Images
/**
* Saves an image from a given URL to a given folder path.
*
* @param {string} url - The URL of the image to save.
* @param {string} folderPath - The folder path where the image should be saved.
* @returns {Promise} - A promise that resolves when the image is saved.
*/
const saveImage = async (url, folderPath) => {
// Get the file name from the URL
const fileName = path.basename(url);
// Construct the full path where the image should be saved
const filePath = path.join(folderPath, fileName);
// Create a write stream for the file
const file = fs.createWriteStream(filePath);
// Fetch the image from the given URL
const response = await fetch(url);
// Pipe the response body to the write stream
response.body.pipe(file);
// Return a promise that resolves when the image is saved
return new Promise((resolve, reject) => {
file.on("finish", resolve);
file.on("error", reject);
});
};
Step 2: Converting Content to Markdown
Once the content is scraped, we convert it to Markdown format using the Turndown library. This makes it easier to maintain and import into Sitecore Content Hub One.
// Create a new instance of TurndownService
// The constructor takes an object with configuration options
const turndownService = new TurndownService({
// Set the heading style to ATX (using # symbols)
// This is the default style used by Markdown
headingStyle: "atx",
// Set the code block style to fenced
// This means that code blocks will be fenced with triple backticks
codeBlockStyle: "fenced",
// Set preformattedCode to true
// This ensures that any preformatted text, such as code blocks, is properly formatted
// when converted to Markdown
preformattedCode: true,
});
// Add custom rule to fence all preformatted text with triple backticks
// This ensures that any preformatted text, such as code blocks, is properly formatted
// when converted to Markdown
turndownService.addRule("fenceAllPreformattedText", {
filter: ["pre"],
replacement: function (content, node, options) {
return (
"\n\n" +
options.fence +
"\n" +
node.firstChild.textContent +
"\n" +
options.fence +
"\n\n"
);
},
});
Step 3: Content Cleanup with AI (Optional)
For enhanced content quality, you can use AI services like ChatGPT to clean and format the content. Here's an example of how to integrate with OpenAI's API:
import { Configuration, OpenAIApi } from "openai";
const cleanupContent = async (content) => {
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const response = await openai.createChatCompletion({
model: "gpt-4",
messages: [
{
role: "system",
content:
"Refine the following blog post content to fix formatting, syntax/grammar errors, etc. while preserving its original meaning and style:",
},
{
role: "user",
content: content,
},
],
});
return response.data.choices[0].message.content;
};
Step 4: Uploading to Sitecore Content Hub One
The final step involves uploading the processed content to Sitecore Content Hub One using their SDK.
Setting Up the Client
import {
ClientCredentialsScheme,
ContentHubOneClientFactory,
ContentHubOneClientOptions,
} from "@sitecore/contenthub-one-sdk";
const createClient = () => {
const options = new ContentHubOneClientOptions(
process.env.CONTENT_HUB_URL,
process.env.CLIENT_ID,
process.env.CLIENT_SECRET
);
return ContentHubOneClientFactory.create(options);
};
Uploading Content
const uploadBlogPost = async (client, blogData) => {
try {
// Create the blog post item in Content Hub One
const contentItem = await createItem(client, {
name: blogData.title,
fields: {
content: {
value: blogData.content,
},
publishDate: {
value: blogData.date,
},
author: {
value: blogData.author,
},
// Add other fields as needed
},
});
// Upload associated images
for (const image of blogData.images) {
await uploadMedia(client, image, contentItem.id);
}
return contentItem;
} catch (error) {
console.error(`Error uploading blog post: ${error.message}`);
throw error;
}
};
Best Practices and Considerations
- 1. Error Handling: Implement robust error handling for both scraping and uploading processes
- 2. Rate Limiting: Respect the source website's robots.txt and implement appropriate delays between requests
- 3. Content Validation: Verify the content structure before uploading to Sitecore
- 4. Media Handling: Ensure all media files are properly processed and linked
- 5. Metadata Preservation: Maintain important metadata during the migration process
Additional Resources
- Sitecore Content Hub One Documentation
- Sitecore XM Cloud
- Puppeteer Documentation
- Cheerio Documentation
- Turndown Documentation
- Content Hub One SDK Reference
Conclusion
Migrating content to Sitecore Content Hub One is a streamlined process that can greatly enhance your content management capabilities. By following this guide and utilizing the provided code examples, you can efficiently transfer content from any website to Sitecore, ensuring a seamless digital experience.
The solution provided here is flexible and can be adapted to various content structures and requirements. Whether you're migrating a small blog or a large corporate website, the principles and approaches outlined in this guide will help you achieve a successful migration.
Remember to test thoroughly in a staging environment before proceeding with the actual migration, and always keep backups of your content throughout the process.