

So welcome to the second part of my learning experiences in migrating content into XM Cloud with the assistance of AI. You can follow the link if you want to read Part 1. The thing about AI is that the smaller the box you put it in the more likely you will be to be successful. The more open ended the task, the more likely you will be disappointed.
Therefore, one of the key elements of using AI is to break down problems into smaller AI capable chunks.
First however, a bit of a self-indulgent diatribe about managing data. In terms of migrating information and putting it into XM Cloud we want that data to be as manageable as possible. If the content editor was a normalized database we would want the data to be as structured as possible. We would want it to be in Boyce Codd Normal Form, or something similar. I.e. data should be atomic, unique and the references between items should be as simple as possible while catering for the business needs.
So, what are these AI capable chunks we can break down Content Migration and Improvement into?
- Well, it can help categorize content. I.e. These pages all look like blog pages, these other pages all look like product pages
- It can help categorize fields of a particular type. I.e. these field looks like it is a first person's name, or this section of a page looks like it is an image of an author.
- It can then create tools to take what it has found and translate it into something else. I.e. take the HTML from the page and extract out the content into a JSON file or take this JSON file and create Sitecore content items out of it.
- It can then create tools which could increase the readability of the content
- It can also create different versions of the content to better target different languages, different market segments, or different personas
- Can improvements be identified into how the data is atomic, unique and the items reference each other.
So, in terms of the above what are we actively using AI for and what are we still researching and training AI to do.
Categorizing Content. So far in the projects I have been involved with the content has been fairly organized. For example, in sites where we had access to the CMS the templates for Blog Articles were consistently used and for sites where we did not have access to the CMS all the blogs existing under a /Blogs content item. This was generally true for most common content types.
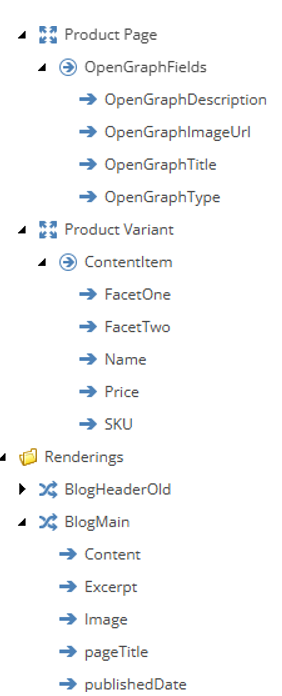
Categorizing Fields. At present we haven’t had sufficient data to train the model AI to do field mapping. Instead, we have created a mapping structure within Sitecore whereby we map fields, renderings, pages from either old content items, or JSON files. With the assistance of AI, we created a Sitecore PowerShell script to map the fields from old to new. Thus creating the new renderings, datasources, and pages etc. See the screenshot to the side for the structure of what these mappings look like. Each of these content items would then have fields which would provide the translation as well as apply any functions to massage the data. I.e. You might scrape the published date from the website but then need it to be translated into ISO format.
Tool Creation. This is where AI was very productive. You can read more about this in the “Part One” article.
Content Readability. This can be done with many of the AI providers that offer an API like OpenAI. You can also just type your text into chat GPT however if migrating a large number of content items this would be very cumbersome, and is not recommended.
Different Versions. This also can be done with many of the AI providers that offer an API.
Data Improvement. This may be the most difficult to achieve as it is reliant of some understanding of what the data is being used for. It requires a little more “real-world” or dare I say “human” experience. Additionally, it would require a very large amount of data to be trained on.
So, in summary, AI can be used to consume data from various sources and import it into XM Cloud. It can then improve or enhance that data. However, it will struggle to organize that data into its most “normalized” form.