

When you publish an item in XM Cloud, the system gathers all the dependencies of that item, converts the data into JSON, and sends it to Edge. This process normally works without any issues. However, if your content tree has a lot of relationship fields—and those fields also have relationship fields—you can quickly run into trouble. You may see longer-than-usual publish times or even crashes on the XM Cloud Content Management (CM) instance. Both problems usually boil down to the number of dependencies the publishing pipeline is trying to handle. In this article, we’ll look at why these issues happen and walk through the options you have for fixing them, from simple tweaks to bigger platform changes. Let’s get started.
What’s going on?
At the time of writing, when a publish operation runs, XM Cloud gathers all the dependencies of an item, serializes the fetched data into JSON, and finally pushes it to Edge. This process usually doesn’t cause any issues, but if you have a content tree that has many relationship fields, whose target items also has more relationship fields, you may quickly run into publishing issues.
Publishing issues you may run into:
- Lengthy Item Publishing
- XM Cloud Content Management System crashes during the publishing operation
In both cases, the root cause is the amount of items/dependency the publishing pipeline is gathering. The more dependencies, the slower. And with enough dependencies, you may consume all the memory available on the CM instance, which will cause it to crash and restart. If you run into the memory issue, you will see an exception in your logs that looks like the following:
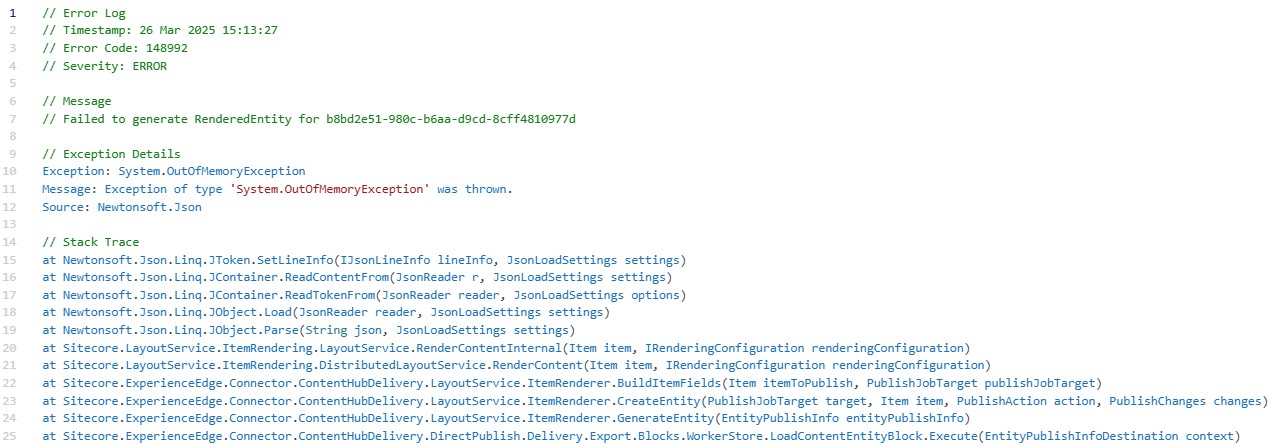
Code in text:
148992 26 Mar 2025 15:13:27 ERROR Failed to generate RenderedEntity for b8bd2e51-980c-b6aa-d9cd-8cff4810977dException: System.OutOfMemoryException Message: Exception of type 'System.OutOfMemoryException' was thrown. Source: Newtonsoft.Json at Newtonsoft.Json.Linq.JToken.SetLineInfo(IJsonLineInfo lineInfo, JsonLoadSettings settings) at Newtonsoft.Json.Linq.JContainer.ReadContentFrom(JsonReader r, JsonLoadSettings settings) at Newtonsoft.Json.Linq.JContainer.ReadTokenFrom(JsonReader reader, JsonLoadSettings options) at Newtonsoft.Json.Linq.JObject.Load(JsonReader reader, JsonLoadSettings settings) at Newtonsoft.Json.Linq.JObject.Parse(String json, JsonLoadSettings settings) at Sitecore.LayoutService.ItemRendering.LayoutService.RenderContentInternal (Item item, IRenderingConfiguration renderingConfiguration) at Sitecore.LayoutService.ItemRendering.DistributedLayoutService. RenderContent(Item item, IRenderingConfiguration renderingConfiguration) at Sitecore.ExperienceEdge.Connector.ContentHubDelivery.LayoutService. ItemRenderer.BuildItemFields(Item itemToPublish, PublishJobTarget publishJobTarget) at Sitecore.ExperienceEdge.Connector.ContentHubDelivery.LayoutService. ItemRenderer.CreateEntity(PublishJobTarget target, Item item, PublishAction action, PublishChanges changes) at Sitecore.ExperienceEdge.Connector.ContentHubDelivery.LayoutService. ItemRenderer.GenerateEntity(EntityPublishInfo entityPublishInfo) at Sitecore.ExperienceEdge.Connector.ContentHubDelivery.DirectPublish. Delivery.Export.Blocks.WorkerStore.LoadContentEntityBlock.Execute (EntityPublishInfoDestination context)
What can we do to mitigate these issues?
Solution
When publishing large and complex content trees, we have a few options within XM Cloud to optimize the process. I would categorize the options available in different tiers.
Tier 1 solutions are easier to implement and change less within the platform.
Tier 2 solutions are not necessarily more complex, but they make much larger underlying changes to the platform. Let’s jump in.
Tier 1 Options
Our tier 1 options will consist of minor changes to how serialization works out of the box. We can modify the serialization depth and how dependencies are calculated. We can make all our changes through a simple patch file. I will show you all the changes within a single patch, but you can pick and choose which ones you want to use. In one of my projects, I implemented all three Tier 1 changes.
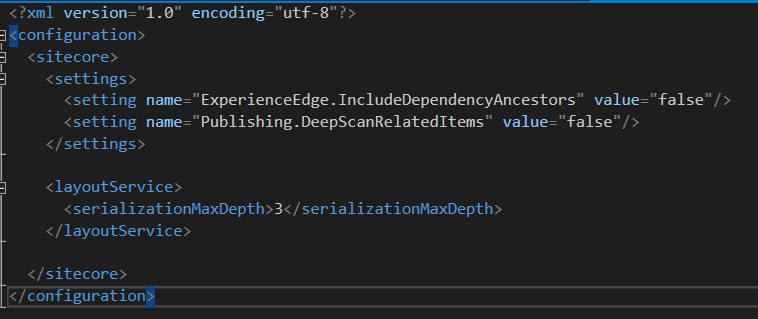
What are all these changes doing?
- ExperienceEdge.IncludeDependencyAncestors: Controls whether during a single item publishing, ancestor items of local data source items are also published to Edge. This is enabled by default.
- Publishing.DeepScanRelatedItems: Controls whether during a publishing operation, if related items are published recursively. If enabled, related items of related items are published. This is enabled by default.
- serializationMaxDepth: Controls the maximum depth for items retrieved in linked (reference) fields. The default value is 4.
In the example above, we disabled IncludeDependencyAncestors and DeepScanRelatedItems and set serializationMaxDepth to 3. These values resolved the publishing issues we were running into but play around with these values to see what the minimal changes are you have to make to resolve your publishing challenges.
Tier 2 Options
When the Tier 1 Options are not sufficient, you may need to explore simple, but larger impacting changes. In this case, our only Tier 2 option is to enable v2 publishing on edge.
Enabling v2 publishing is a straightforward process:
1. In XM Cloud Deploy App, navigate your project and environment
2. Add environment variable “Sitecore_ExperienceEdge_dot_WorkerStoreEnabled” with a value of “TRUE”
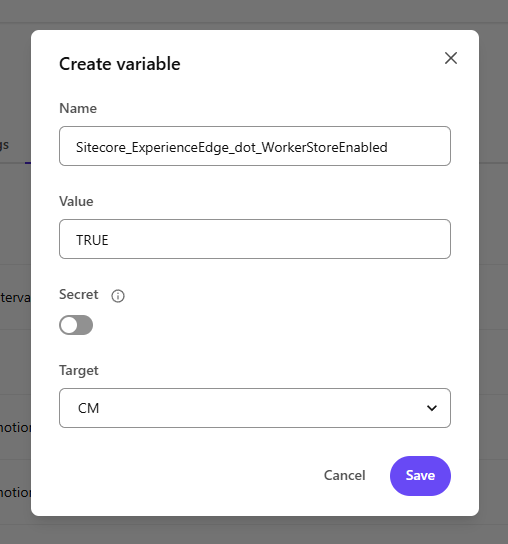
3. Deploy the environment

4. Republish all sites on the environment
While we saw speed improvement by enabled v2 publishing, it was the Tier 1 changes listed in the previous section that fixed our publishing operations crashing the CM server. As a result, we reverted to v1 publishing. But every project is unique, and v2 may be the solution you’re looking for.
For more details around v2 publishing, refer to the XM Cloud v2 Publishing documentation.
Conclusion
Publishing large and complex trees in XM Cloud can pose some challenges, but you have several tools at your disposal to address them. Tier 1 changes let you keep most of your current setup, while Tier 2 offers a more structural adjustment to Edge publishing. The right combination depends on your project’s specific needs and constraints. By experimenting with these options, you can streamline your publishing process, prevent crashes, and ensure that your content gets where it needs to go without unnecessary delays.